
Rootkits eBPF & forensic : de l’aveuglement de la télémétrie à la détection mémoire
Abstract
Les eBPF sont une fonctionnalité incroyable du noyau Linux mais aussi dangereuse ! Souvent méconnus, les eBPF permettent de créer des programmes malveillants capables de se cacher eux-mêmes. À la fin de l’article, je propose une méthode d’analyse en mémoire qui exploite la structure des rootkit eBPF pour les détecter.
Dans cet article nous allons voir :
- comment fonctionnent les eBPF
- l’architecture théorique d’un malware eBPF
- blocage de télémétrie via l’usage d’un rootkit eBPF
- forensic : trouver notre rootkit dans un dump mémoire
Je vous souhaite une excellente lecture !
Les eBPF
Présentation des eBPF
Les eBPF sont une fonctionnalité qui a été ajoutée au noyau Linux en 2014 et dont l’implémentation continue encore d’évoluer. L’idée révolutionnaire derrière ce système est de permettre la modification de comportement du noyau avec une autre interface que celle que nous utilisions historiquement : le développement de driver. Et en plus les eBPF ont un magnifique logo ;)

Plus concrètement, on va venir installer des hook dans le kernel Linux afin d’observer et de modifier certains comportements. Pour cela on peut utiliser ce qu’on appelle un hook. Un hook est simplement la modification d’un programme pour détourner son flow vers une fonction secondaire.
Il existe de nombreux types de hook en eBPF, notamment :
kprobes : kernel probes, permet de hooker quasiment n’importe quelle instruction dans le kernel linux. Il existe cependant une blacklist d’adresses. Pour cela on utilise register_kprobe() et unregister_*probes().
Return probes : permet de hooker le retour d’une fonction en remplaçant son adresse de retour par ce que la doc appelle un “trampoline”.
Tracepoint : points d’instrumentation statiques dans le kernel, préinsérés par les développeurs du kernel. Beaucoup moins gourmands en performance.
Le hook cgroup : attache un eBPF à un cgroup (v2) : le programme s’exécute alors pour tous les processus de ce groupe. Cela permet d’observer ou de filtrer des comportements à la granularité d’un conteneur ou d’un service plutôt que pour tout le système. Par exemple sur les paquets réseau (cgroup/skb), la création de sockets (cgroup/sock), les adresses de connect/bind (cgroup/sockaddr), les sysctl ou l’accès aux périphériques (cgroup/device).
Note : Pour gérer nos eBPF, un syscall dédié a été ajouté dans le noyau linux : le syscall eBPF.

eBPF hook ( faut bien rigoler )
Exemple d’usage des eBPF
Beaucoup de projets d’observabilité se sont basés sur la technologie des eBPF pour renforcer la sécurité de nos systèmes : on peut citer Cilium et Falco notamment. À la manière de Sysmon pour Linux, ils vont venir observer ce qui se passe dans le noyau afin de détecter des comportements suspects.
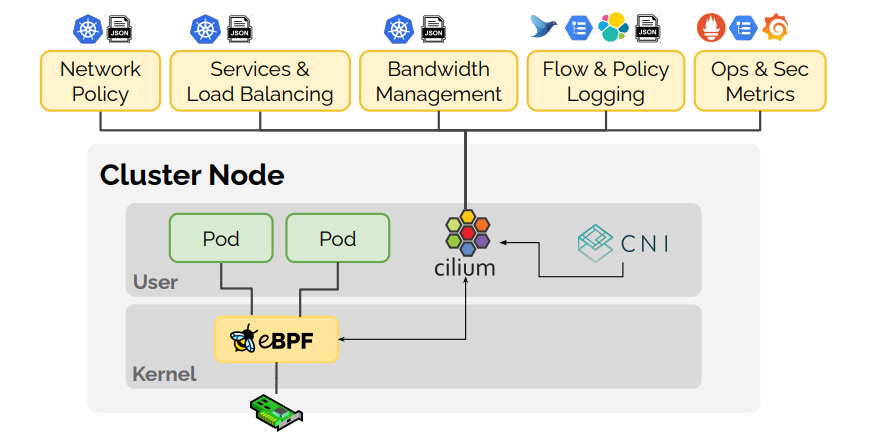
Utilisation des eBPF pour l’observabilité, ref : https://hub.docker.com/r/cilium/docker-plugin
Un des grands avantages de ce système est que cela convient très bien dans les architectures modernes de conteneurisation de docker à kubernetes. En effet, le noyau étant partagé entre les conteneurs, surveiller l’hôte revient à surveiller tous les invités.
Les eBPF sont également utilisés pour modifier les comportements du noyau. Par exemple Katran, développé par Meta, est un exemple très parlant : il s’agit d’un load-balancer L4 haute performance basé sur XDP/eBPF, capable de traiter les paquets très tôt dans le chemin réseau. Dans la même famille, LoxiLB propose un load-balancer cloud-native basé sur Go et eBPF.
Les eBPF XDP
Pour continuer sur les noms absconds, faisons un détour introductif pour parler des eBPF XDP. Les XDP sont un type d’eBPF qu’on va utiliser plus bas et qui permettent spécifiquement de travailler sur la couche réseau.
Très puissants, ils peuvent même être directement chargés sur la carte réseau. C’est idéal pour implémenter des outils de load-balancing ou bien de firewall.
Le problème
Et oui ! C’est le retour du grand méchant ( introduit dans l’article précédent : https://nobisd.fr/posts/dfir-graphes-threat-hunting/ ). Évidemment, si nos eBPF peuvent être utilisés pour modifier directement le noyau, les vilains peuvent le faire aussi. C’est une manière flexible et relativement discrète de persister et de cacher ses processus, communications malveillantes, etc…
Cette classe de malware logés dans le kernel c’est ce qu’on appelle un rootkit. Le scénario de menace est celui d’un attaquant qui a réussi à s’élever en tant que root sur la machine et qui veut désormais se cacher. L’accès au kernel lui sert souvent pour masquer la suite de son activité malveillante.
Anatomie d’un rootkit eBPF
Ici une présentation théorique de la façon dont s’articule un rootkit eBPF minimal.
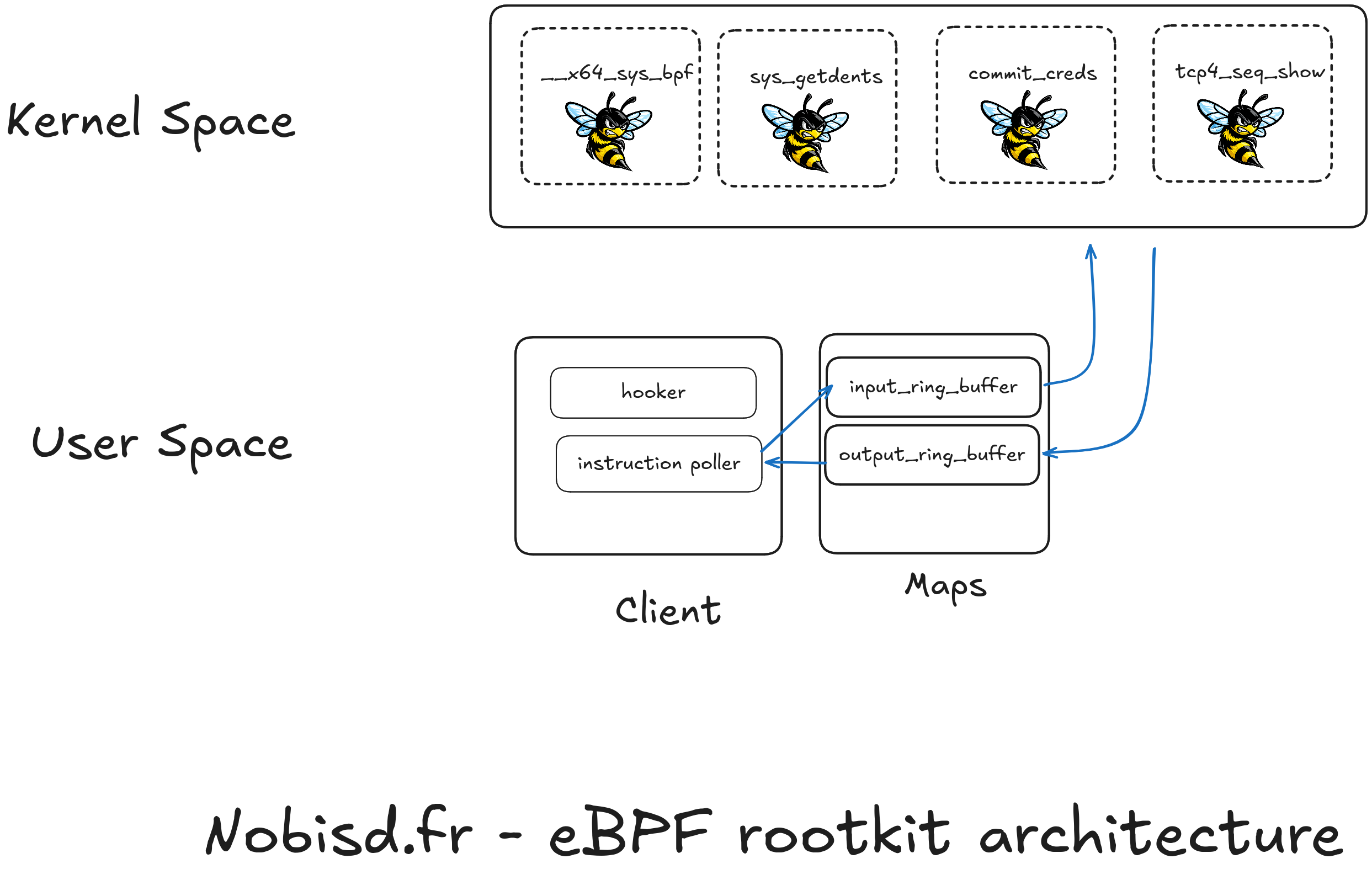
Comme présenté ci-dessus, notre rootkit va devoir s’articuler en deux parties : une dans l’espace utilisateur ( user-space ) et une autre dans l’espace noyau ( kernel-space ).
Espace utilisateur
Processus client
Notre rootkit va devoir avoir deux éléments importants : un processus qui va communiquer avec les eBPF chargés dans le noyau, et les maps qui sont un espace partagé avec nos programmes eBPF.
Le programme client, pourra être dirigé à distance par un attaquant ( via un canal de command and control ) ou bien seulement avoir pour objectif de charger les eBPF dans le noyau et leur passer des ordres. En effet, pour charger nos eBPF malveillants il va falloir passer par le syscall eBPF pour que le kernel vérifie nos eBPF afin d’éviter que ceux-ci présentent des risques de faire planter le système. Si ceux-ci passent les tests ils seront chargés dans la machine virtuelle eBPF et attachés à un kprobe. Pour pouvoir charger un eBPF un programme devra déjà être exécuté en tant que root.
Les maps
Les maps sont un espace mémoire partagé qui permet d’échanger des données entre un programme en espace utilisateur et des eBPF. Il existe différents types de map selon les données qu’on essaye d’échanger mais les ring buffer permettent généralement de répondre aux cas client-serveur.
On distingue deux manières d’utiliser les map : les pinned-map ou les not-pinned. Si la map est attachée ( pinned :D dur dur d’écrire en français ), celle-ci possède un descripteur de fichier ouvert dans /sys/fs/bpf/ et qui peut rendre plus visible le rootkit. Cependant, si la map n’est pas attachée, dès le déchargement des eBPF clients ou programme qui les a chargé, la map disparaît. Si le développeur du rootkit veut privilégier la stabilité, il a tout intérêt à garder ses maps attachées.

Pinned map
Espace noyau
C’est ici que tout se joue, en insérant des eBPF aux endroits stratégiques le rootkit va pouvoir cacher les processus malveillants, cacher ses fichiers et ses connexions réseau. En échangeant avec le client via les map, chaque eBPF va prendre ses instructions pour savoir que cacher, quoi modifier, etc…
On peut citer quelques kprobe d’importance ( présents aussi dans le schéma plus haut ) :
__x64_sys_bpf : c’est la fonction exécutée par le syscall bpf, ici on pourra modifier son comportement pour cacher les eBPF malveillants
sys_getdents : fonction exécutée pour lister les fichiers d’un dossier (et les processus) ; la détourner permettrait de cacher les maps ou fichiers malveillants, ainsi que le processus client
commit_creds : chargée de la gestion des autorisations des processus, elle pourrait être détournée pour faire tourner tous les processus de l’attaquant en root
tcp4_seq_show : pourrait permettre de cacher les connexions tcp de l’attaquant
À la découverte de nouveaux symboles noyaux
Pour trouver de nouveaux symboles hookable et lister ceux du noyau on peut directement lire en root le fichier /proc/kallsyms .
Ex :
theo@theo-rootkit:~$ sudo cat /proc/kallsyms | grep bpf | head
000000000002bac0 A bpf_raw_tp_nest_level
000000000002bae0 A bpf_raw_tp_regs
000000000002bd40 A bpf_misc_sds
000000000002c040 A bpf_pt_regs
000000000002c238 A bpf_event_output_nest_level
000000000002c23c A bpf_trace_nest_level
000000000002c240 A bpf_trace_sds
000000000002c550 A bpf_user_rnd_state
000000000002c560 A __bpf_map_cookie
000000000002c570 A bpf_prog_active
Se défendre contre les rootkit eBPF
C’est ici que les choses deviennent compliquées. Cette fonctionnalité a beau être révolutionnaire elle pose un certain nombre de problèmes.
Comparaison avec Windows
Dans Windows, atteindre l’exécution kernel est beaucoup plus compliqué : il faut passer par un driver signé — le plus souvent en exploitant un driver légitime mais vulnérable (technique du BYOVD, Bring Your Own Vulnerable Driver). Pas impossible, mais vraiment pas évident. De plus, avec des protections comme HVCI / VBS (intégrité du code garantie par l’hyperviseur) et DSE (signature obligatoire des drivers), même un driver chargé ne dispose pas des mêmes libertés dans l’espace noyau. En bref, Linux expose une surface d’extension kernel très puissante, dont la sécurité dépend fortement de la configuration : capabilities, lockdown, LSM, unprivileged BPF, Secure Boot, visibilité bpftool, etc.
Le kernel-lockdown
Une protection permet d’empêcher le chargement d’eBPF dans le kernel : le kernel lockdown. Disponible en deux modes : integrity ou confidentiality, cette fonctionnalité est désactivée par défaut. En mode integrity, le kernel empêche le chargement d’eBPF qui modifient le comportement du noyau et les drivers non signés. En mode confidentiality, le kernel restreint en plus les eBPF capables de lire la mémoire du noyau (typiquement ceux attachés à des kprobe via les helpers de lecture), afin d’éviter toute fuite d’information depuis le noyau.
En confidentiality, il reste donc les eBPF de type tracepoint (uniquement pour l’observabilité) et XDP ( la partie réseau).
On peut vérifier le mode actuel ainsi :
cat /sys/kernel/security/lockdown
[none] integrity confidentiality
Ci-dessus les petits [] m’indiquent que je suis en mode none, sans lockdown.
Remarque : la plupart des distributions majeures activent le kernel lockdown en integrity quand le secure-boot est activé dans l’UEFI. C’est donc une fonctionnalité répandue.
La parade de l’attaquant : désactiver la télémétrie distante
Comme on l’a vu précédemment, malgré le kernel lockdown on devrait être capables de charger des eBPF de type réseau : les XDP, mais aussi les programmes attachés à un cgroup (cgroup_skb), qui ne sont couverts par aucun des deux modes de lockdown. C’est ce dernier type que nous allons utiliser ici. Un attaquant pourrait s’en servir par exemple pour empêcher le système d’envoyer ses logs au serveur central, ou pour y introduire un peu d’entropie.
Afin de tester ce modèle on va déployer un petit range avec ludus ( voir mon article sur le sujet https://nobisd.fr/posts/ludus-proxmox/ ). On va simplement avoir une machine victime avec falco déployé dessus qui envoie ses logs à un serveur elk central.
Commençons par activer le kernel-lockdown en integrity :
sudo vim /etc/default/grub
# mettre cette ligne GRUB_CMDLINE_LINUX_DEFAULT="quiet lockdown=integrity"
# Puis
sudo update-grub
sudo reboot
On installe ensuite falco et on active le service. Falco est un outil très puissant pour obtenir de la visibilité sur ce qu’il se passe sur un système Linux. On peut le comparer à auditd, dont il est une version plus moderne. Falco peut tourner en plusieurs modes, dont en eBPF pour obtenir sa vision sur le kernel.
Ici on peut voir que falco tourne bien en eBPF :
sudo systemctl cat falco | grep engine
ExecStart=/usr/bin/falco -o engine.kind=modern_ebpf
Si on fait des actions malveillantes par exemple cat /etc/passwd on voit qu’on reçoit bien les logs dans notre SIEM :
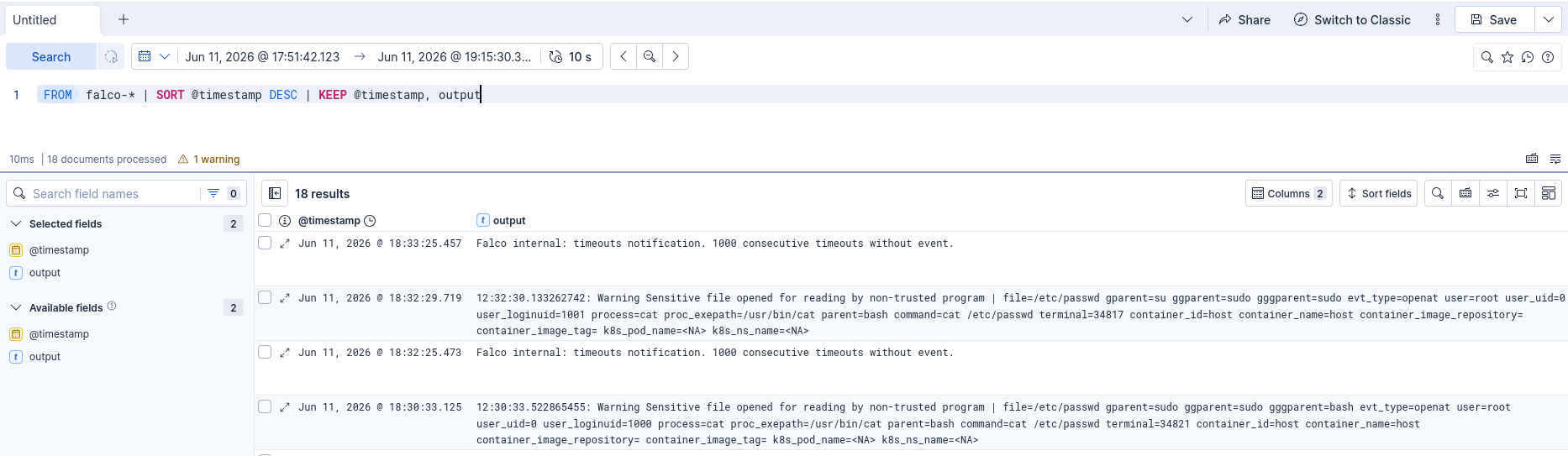
Chargement d’un rootkit eBPF dédié
Cette fois on utilise un petit programme écrit spécialement pour ça et disponible ici dans le lab du post : https://github.com/theophane-droid/dfir-ebpf-rootkit/.
En dehors de la logique d’échange de données avec la map, le programme bpf gère le blocage des flux ici :
static __always_inline int handle_packet(struct __sk_buff *skb, __u8 direction)
{
...
if (!rule_matches(rule, dport, direction))
continue;
dropped = should_drop_flow(rule,
ip.saddr,
ip.daddr,
sport,
dport,
ip.protocol,
direction);
emit_event(skb, &ip, sport, dport, idx, direction, rule, dropped);
return dropped ? 0 : 1;
}
return 1;
}
SEC("cgroup_skb/ingress")
int on_ingress(struct __sk_buff *skb)
{
return handle_packet(skb, DROP_DIR_INGRESS);
}
SEC("cgroup_skb/egress")
int on_egress(struct __sk_buff *skb)
{
return handle_packet(skb, DROP_DIR_EGRESS);
}
Dans le loader (client) on fera ceci pour attacher l’ebpf à l’entrée sortie d’un cgroup spécifique. Ici on utilise le cgroup par défaut afin de n’impacter que les processus de l’host.
skel->links.on_ingress = bpf_program__attach_cgroup(
skel->progs.on_ingress,
cgroup_fd
);
skel->links.on_ingress = bpf_program__attach_cgroup(
skel->progs.on_ingress,
cgroup_fd
);
On peut le lancer afin d’aveugler falco :
./loader
listening on cgroup: /sys/fs/cgroup
stats interval: 5s
configured drop rules:
rule=0 port=50000 direction=out drop=100%
stats:
rule=0 port=50000 direction=out configured_drop=100% matched=0 dropped=0 passed=0 observed_drop=0.0%
stats:
rule=0 port=50000 direction=out configured_drop=100% matched=6 dropped=6 passed=0 observed_drop=100.0%
On voit ici que les connexions sortantes de falco sont bien bloquées et notre console SIEM ne reçoit plus de logs. Bloquer l’intégralité du flux est volontairement grossier ici, à des fins de démonstration — un SIEM mature pourrait s’alarmer de l’arrêt brutal des logs ; on verra plus bas comment raffiner. Pourtant, le kernel-lockdown est bien activé ! On peut maintenant supprimer les logs falco si on veut faire du log tampering.
rm -rf /var/log/falco/*
Ce que ça montre du verrouillage kernel
Comme nous l’avons vu dans cette section, le kernel a beau avoir le lockdown d’activé. Il y a tout de même des possibilités d’aveugler la télémétrie. Étant donné que falco démarre un serveur web qui permet de vérifier s’il est toujours en vie, le serveur central pourra toujours penser que le serveur fonctionne normalement.
On pourrait même aller plus loin : plutôt que de bloquer tous les flux, on pourrait filtrer le corps des messages et bloquer tout ce qui concerne des alertes et laisser passer le reste du contenu. C’est d’ailleurs ici que les eBPF peuvent se montrer plus intelligents pour faire de l’aveuglement qu’une règle de filtrage qui bloquerait la télémétrie.
Forensic
C’est pas mal ! Nous avons pu voir comment un attaquant pouvait utiliser les eBPF à son avantage pour nous aveugler. Comment pourrions-nous détecter une telle attaque ?
Pour les rootkit eBPF on peut faire le tableau suivant concernant la fiabilité de l’investigation :
| Approche | Fiable si kernel compromis ? | Intérêt |
|---|---|---|
bpftool live | Non | Tri rapide |
/sys/fs/bpf | Non | Artefacts faciles |
| Falco/Tetragon | Partiel | Détection avant aveuglement |
| AVML depuis l’OS | Moyen | Pratique si lockdown permet |
| LiME | Moyen | Puissant mais lourd |
| Dump hyperviseur | Oui | Meilleur choix lab/cloud |
| Volatility + symboles exacts | Oui si dump fiable | Analyse post-mortem |
Donc si on a une suspicion de compromission du kernel, l’idéal est de réaliser un dump mémoire depuis l’hyperviseur.
Réaliser le dump et générer les symboles
Le dump est pris directement depuis l’hyperviseur Proxmox, sans rien exécuter sur la machine potentiellement compromise (le lab tourne sous Proxmox, déployé avec Ludus ; voir mon article dédié) :
qm monitor <vmid>
qm> dump-guest-memory /var/lib/vz/dump/mem-<vmid>.elf
qm> quit
Volatility a besoin de symboles correspondant exactement au noyau du dump. On récupère donc d’abord sa version :
strings memory.dump | grep -i "Linux version"
On télécharge ensuite les paquets dbgsym Debian correspondants, puis on génère le fichier de symboles (ISF) avec dwarf2json :
dwarf2json linux \
--elf ./vmlinux-6.1.0-49-amd64 \
--system-map ./System.map-6.1.0-49-amd64 \
> linux-6.1.0-49-amd64.json
mkdir -p symbols/linux
mv linux-6.1.0-49-amd64.json symbols/linux/
Il ne reste plus qu’à pointer Volatility (et volshell) sur ce dossier de symboles, et à dérouler l’analyse.
Stratégie de détection
Comme cela a été montré plus haut, un rootkit ebpf est composé de nombreuses briques entre le kernel et l’espace utilisateur. Plutôt que d’aller analyser chacune des briques, pour savoir si elle est malveillante, j’explore ici la stratégie de repérer les liaisons entre chaque brique telle que montré ici :
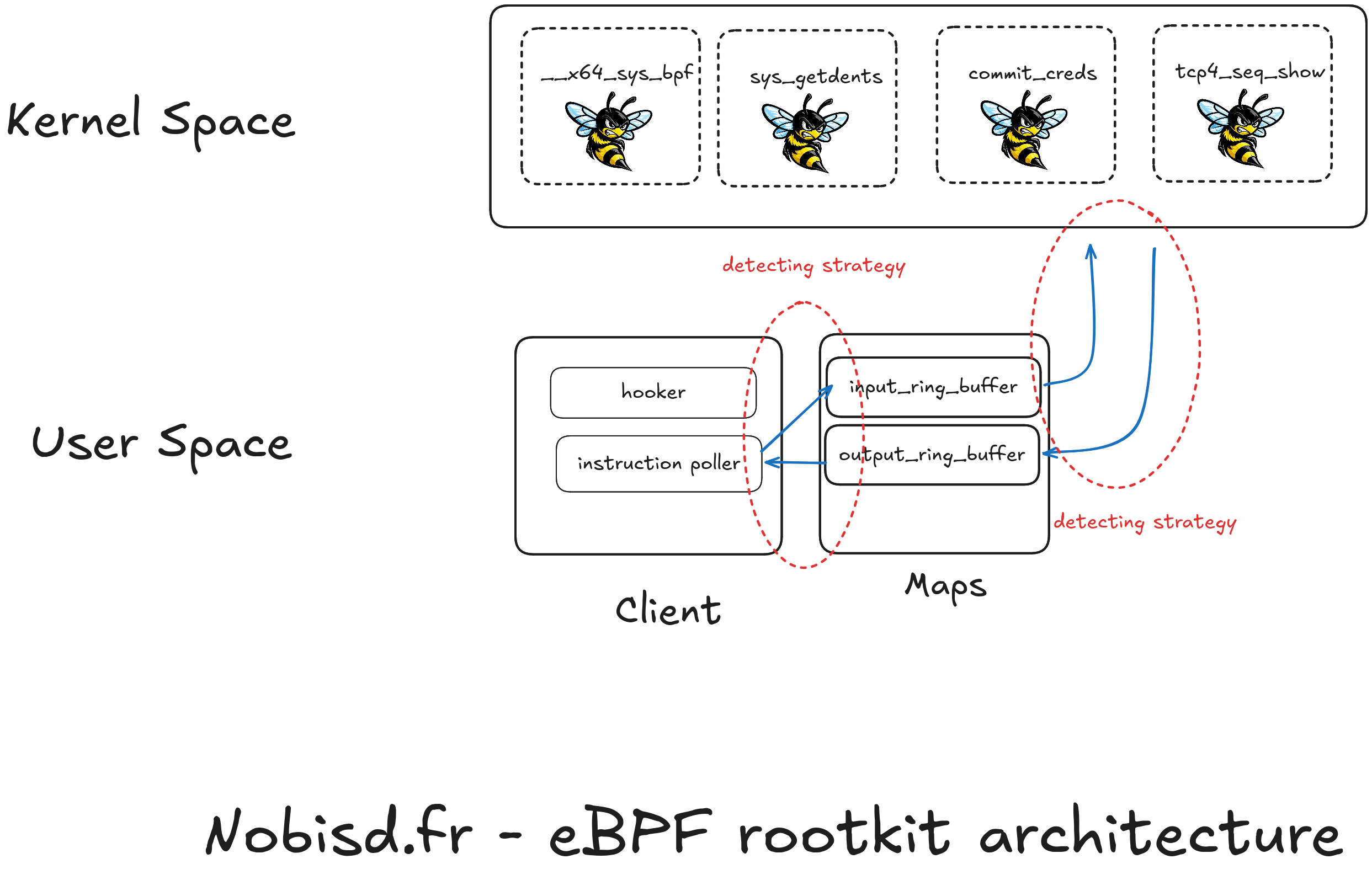
Étant donné que les processus clients, doivent maintenir une map ouverte et que les eBPF également, cette relation peut être exploitée pour savoir quel processus utilise quelle map et donc au final à quel eBPF il s’adresse.
Detection client - map
En effet, les processus utilisateurs maintiennent des files descriptor ouverts vers les map qu’ils utilisent même si celles-ci ne sont pas pinnées. Ces files descriptor sont visibles en mémoire et peuvent être explorés avec volatility 3 par exemple. En utilisant la fonction lsof fournie par l’API volatility, on va pouvoir explorer tous les fichiers ouverts et basé sur leur type sélectionner ceux qui concernent des map eBPF.
Detection eBPF - map
Pour trouver les liens entre nos eBPF et les maps, on va pouvoir utiliser le module volatility nommé linux.ebpf celui-ci liste tous les eBPF chargés dans le noyau. Pour chaque programme chargé en mémoire, le kernel maintient une liste des maps ouvertes dans un tableau. Ce tableau se trouve en parcourant les deux structures successives : prog->aux->used_maps .
Relier les deux
Une fois connus les clients et leurs relations avec des maps, et les maps et leur relation avec des eBPF, on peut désormais tracer la relation entre les programmes utilisateurs et les eBPF. Cela va nous aider à dire si l’eBPF est légitime ou non, basé sur le programme qui l’utilise.
L’automatisation
Pour automatiser cela, j’ai développé un script disponible sur le repository de ce lab ici : https://github.com/theophane-droid/dfir-ebpf-rootkit/. On peut simplement l’utiliser ainsi :
volshell -f mem-dump -s ./symbols/ -l --script find_evil_ebpf.py
Volshell (Volatility 3 Framework) 2.28.0
Readline imported successfully Stacking attempts finished
Running code from file:///home/theo/memory/analysis_script.py
======================================================================
Table 1 : file descriptors pointing to eBPF maps
======================================================================
[*] 17 fds pointing to eBPF maps found.
PID TID COMM FD MAP_ID TYPE NAME ADDRESS
------------------------------------------------------------------------------------------
407 407 falco 77 36 PROG_ARRAY custom_sys_exit 0x88ce0691ba00
407 407 falco 78 37 PROG_ARRAY syscall_exit_ta 0x88ce0333e000
407 407 falco 79 38 PROG_ARRAY syscall_exit_ex 0x88ce0691b400
407 407 falco 80 39 ARRAY interesting_sys 0x88ce0333a000
407 407 falco 81 40 ARRAY capture_setting 0x88ce0691bc00
407 407 falco 82 41 ARRAY iter_auxiliary_ 0xcf02c4245000
407 407 falco 83 42 ARRAY iter_counters_m 0x88ce0691b200
407 407 falco 84 43 ARRAY auxiliary_maps 0xcf02c4267000
407 407 falco 85 44 ARRAY counter_maps 0x88ce0283d800
407 407 falco 86 45 ARRAY_OF_MAPS ringbuf_maps 0x88ce0691a000
407 407 falco 87 46 PROG_ARRAY extra_sched_pro 0x88ce0691b800
407 407 falco 88 47 ARRAY bpf_prob.rodata 0xcf02c42a9ef0
407 407 falco 89 48 ARRAY bpf_prob.bss 0xcf02c4359ef0
407 407 falco 90 49 ARRAY bpf_prob.data 0xcf02c435cef0
693 693 loader 4 51 RINGBUF events 0x88ce0124f800
693 693 loader 5 52 ARRAY rule_count 0x88ce0124e600
693 693 loader 6 53 ARRAY drop_rules 0x88ce0ae22400
======================================================================
Table 2 : eBPF programs and the maps they use
======================================================================
[*] 918 program/map associations found.
PROG_ID PROG_NAME PROG_TYPE MAP_ID MAP_TYPE MAP_NAME
------------------------------------------------------------------------------------------
3 sd_devices CGROUP_DEVICE - -
4 sd_fw_egress CGROUP_SKB - -
5 sd_fw_ingress CGROUP_SKB - -
6 sd_fw_egress CGROUP_SKB - -
7 sd_fw_ingress CGROUP_SKB - -
8 sd_devices CGROUP_DEVICE - -
...
237 on_ingress CGROUP_SKB 53 ARRAY drop_rules
237 on_ingress CGROUP_SKB 51 RINGBUF events
238 on_egress CGROUP_SKB 52 ARRAY rule_count
238 on_egress CGROUP_SKB 53 ARRAY drop_rules
238 on_egress CGROUP_SKB 51 RINGBUF events
======================================================================
Table 3 : user processes linked to eBPF programs via shared maps
======================================================================
[*] 909 process <-> program links via shared maps.
PID COMM PROG_ID PROG_NAME MAP_ID MAP_TYPE SHARED_MAP_NAME
-----------------------------------------------------------------------------------------------
407 falco 36 sys_exit 36 PROG_ARRAY custom_sys_exit
407 falco 36 sys_exit 37 PROG_ARRAY syscall_exit_ta
407 falco 138 open_by_handle_ 38 PROG_ARRAY syscall_exit_ex
407 falco 207 vfork_x 38 PROG_ARRAY syscall_exit_ex
...
693 loader 237 on_ingress 51 RINGBUF events
693 loader 238 on_egress 51 RINGBUF events
693 loader 237 on_ingress 52 ARRAY rule_count
693 loader 238 on_egress 52 ARRAY rule_count
693 loader 237 on_ingress 53 ARRAY drop_rules
693 loader 238 on_egress 53 ARRAY drop_rules
Ci-dessus, on peut voir qu’il a été possible de :
- table 1 : lister tous les programmes ayant une map eBPF ouverte et chaque map utilisée par un eBPF. Ainsi, nous avons pu identifier deux programmes utilisateurs qui utilisent les eBPF :
falco (pid 407)etloader (pid 693). - table 2 : lister toutes les maps tenues par des programmes eBPF
- table 3 : faire le lien entre les process utilisateurs et les programmes eBPF via leur map
On peut ensuite investiguer davantage sur les deux processus falco et loader, pour savoir dans quel contexte ils ont été lancés. Cette analyse permettrait de montrer que loader est bien malveillant et que tous les eBPF qu’utilise ce programme sont donc malicieux.
Limite de cette approche
Il est tout à fait possible d’imaginer des rootkit eBPF qui n’utiliseraient pas de maps pour communiquer avec un programme utilisateur. Un tel eBPF pourrait être injecté avec des paramètres dynamiquement choisis selon les besoins de l’opérateur malveillant.
Conclusion
Dans cet article, nous avons pu montrer que malgré les protections noyaux qui peuvent être mises en place, la menace des rootkit eBPF n’est pas éteinte. De ce constat, nous avons pu montrer une méthode pour tracer le lien entre les processus utilisateurs et les eBPF pour faire la différence entre un programme légitime et un rootkit.
J’espère que cet article vous a plu, j’explore ce format qui se veut à mi-chemin entre la vision d’un attaquant et celle d’un analyste forensic. Si cela vous a plu n’hésitez pas à me suivre et à me faire des retours sur linkedin : https://linkedin.com/in/theophane-dumas.
À bientôt sur nobisd pour plus d’articles forensic !